

AI-Assisted Detection System for High Risk Messages in Social Media
自然語言處理應用於社群網路貼文自殺風險預測
一、背景說明
根據台灣自殺防治學會的資料,110年全國共有3,656人自殺死亡,位未列死因排名的第11名。參考台北市政府自殺防治中心資料則可以發現,全世界每年約有70萬人死於自殺,1,000-2,000萬人嘗試自殺,5,000萬-1億2,000萬深受自殺或有一個近親或同事企圖自殺的影響,此外,全世界60%的自殺案件都來自亞洲,足見自殺防治是我們需要更積極關注的議題。
而觀察目前常見的自殺意念量表多採用自評或他評形式,需回答特定問題,較難用於分辨網絡文本的危機程度。因此本計畫基於具匿名性,且只開放給台灣跟海外部分大學學生註冊,同時廣受年輕族群歡迎的社群網絡平台Dcard,使用Dcard心情版或感情版上文章資料作為研究對象和訓練資料集,訓練模型,預測網絡文章的自殺與憂鬱危機程度。
二、計畫簡介
本計畫旨在應對日益嚴重的自殺問題,特別針對年輕人在社群網絡上的言論進行分析,以提早發現自殺危機,進而提供協助。我們注意到現有的自殺意念量表對於網絡文本的應用受到限制,因此我們以受年輕人歡迎的社群網絡平台Dcard 2019年心情版和感情版文章作為資料集,訓練社群網路貼文自殺風險偵測系統。
計算文章的情緒指數後,在心理諮商專業人員的指導下,對文章進行類型標註和語意標註,以區分文章的危機程度和語句內容意義。在此基礎上,我們採用預訓練模型BERT建立自殺風險偵測系統的架構,使用標註後資料進行微調。
我們的研究聚焦於在於語意分類模型和文章分類模型的建立。語意分類模型目標提取重要的文句標籤,以協助預測文章的危機程度,而文章分類模型則是將文章分為高度危機和中低危機兩類。研究結果顯示,我們的模型在偵測高度危機文章方面取得了相當高的準確度,但仍需進一步改進以提高召回率,減少漏報的情況。
本計畫為解決網絡文章自殺危機提供了一個初步的解決方案,未來,我們將繼續改進模型,提高準確度和召回率,並且期望與各領域專家及社群媒體平台進一步合作,構建一個更加關懷與健康的社群媒體環境。
三、資料來源與標註
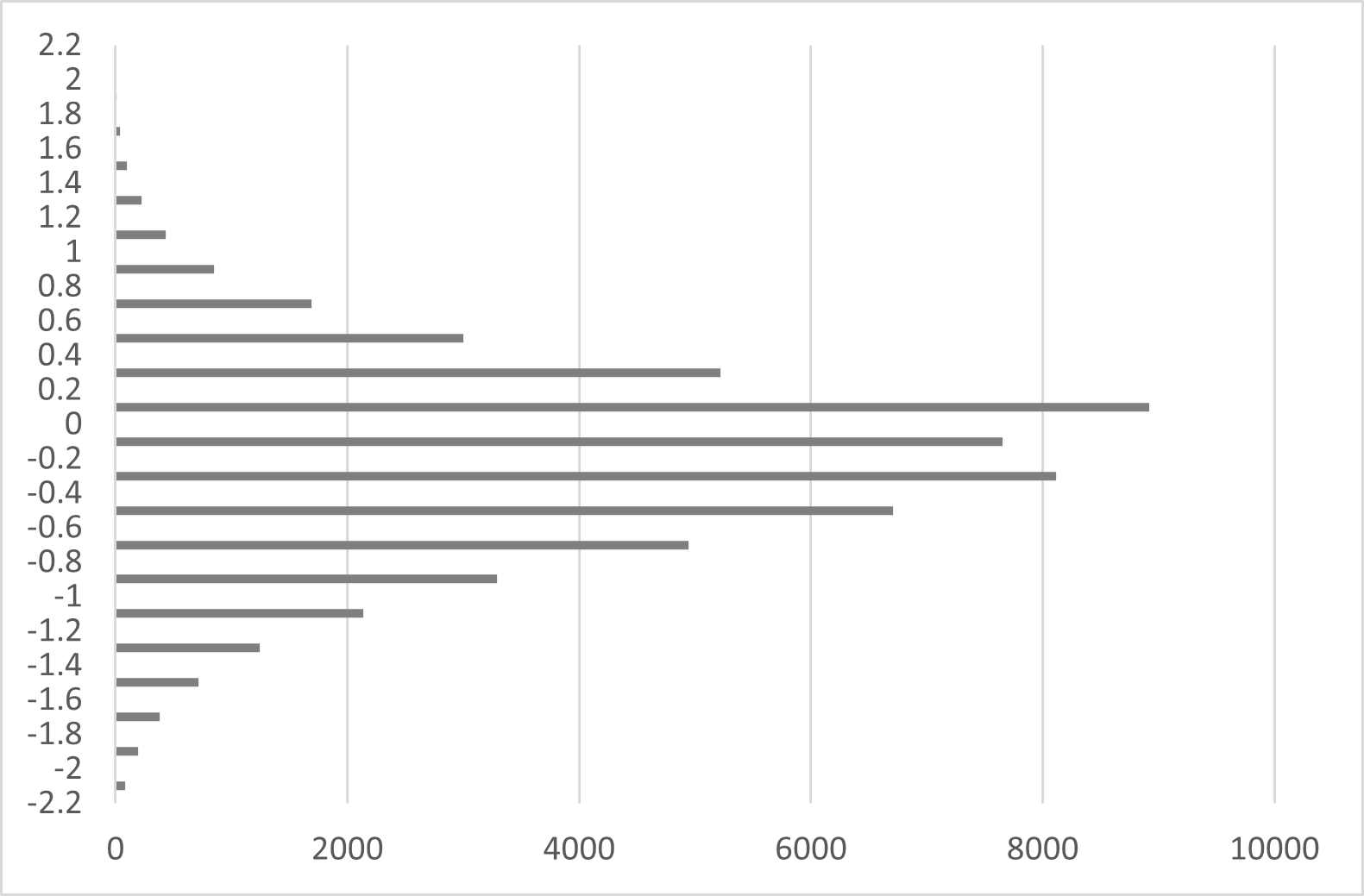
本計畫使用爬蟲工具蒐集 Dcard心情板與感情板2019年全年共55989篇文章的標題與內文作為資料庫(database),再依據National Taiwan University Semantic Dictionary(NTUSD)的情緒辭典[1] 評估文章的正負向情緒指數,計算每篇文章的總得分再除以總字數作為此文章的平均情緒指數,篩選指數低於-1.4的1424篇較負向的文章進行資料標註,文章數量分布表一。
圖表一、2019年Dcard心情板與感情版文章之正負向情緒指數分布情形。
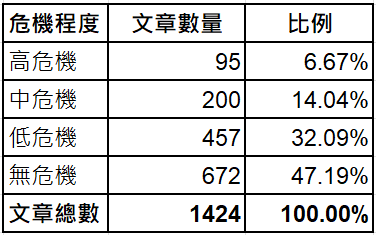
標註部分在心理諮商領域的李昆樺教授指導下,使用文字標註平台[2] ,分為類型標註與語意標註兩部分進行,其中,類型標註部分,將文章依照其內容分為高度危機、中度危機、低度危機、無危機四個等級,其中高危機代表有明確的自殺行為或具體行動,中度危機代表有明確的自殺規劃或預備,低度危機代表有自殺的意圖或想法,無危機代表雖可能有各種情緒但是並無自殺的意圖[3] ,文章參考表二。
圖表二、專業人員針對A1文章做類型標註後,各類型文章的數量與佔比。
圖表三、文章電腦斷句方式示意圖。

而語意分類目標則為幫助進行文章類型預測,針對文章中每個意義完整的句子進行初步標註,在不規範標註文句長度情況下,選出(1)自殺或自傷行為、(2)憂鬱與自殺意念、(3)無助感或無望感、(4)生理或醫療狀況、(5)其他負向文字、(6)正向積極文字等六種類型的句子,並將其餘的標註為(7)中性或其他文字。統計初步標註句子可以發現,平均長度為34⋅64字的句子可表達完整的語意。接著根據圖一示意的斷句方式,將文章斷句後,對斷句後句子再次進行標註,若單一句子同時符合多個標註,則以上述的順序優先選出次序最前的類別做為此句的標註。
四、系統架構
圖表四、網路貼文自殺風險偵測系統架構圖。
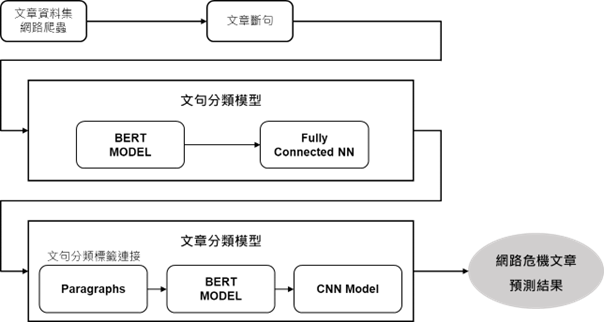
預訓練模型使用人工智慧下,自然語言處理技術(Natural Language Processing)中被廣泛使用的BERT(Bidirectional Encoder Representations from Transformers)[4] ,使用標註結果進行微調(fine-tune)。然觀察表一、表二、表三可以發現資料集的分布非常不平均(與一般資工領域作為標準練習或比賽而篩選過的資料不同,實際資料真實樣貌大多如此,並非本研究問題)。以文章類型標註為例,「高度危機」文章僅有70篇,但「無危機」文章僅有712篇;再看到語意標註,「其他負向文字」有7362句,「自殺或自傷行為」卻僅有139句,數量上差距甚大。總上所述,資料集的實際情況使資料數量不多與資料分布不均勻成為開發模型過程中遇到的主要問題,因此我們針對資料進行資料擴增(Data Augmentation),並結合半監督式模型(Semi-Supervised Learning)的技術來協助模型開發。
五、語意分類模型
本為幫助進行文章分類預測,我們提取重要的文句標籤做語意標註分類,不以強化所有類型的語意標籤為模型優化目標,以節省時間與計算資源。本計畫先以其他較為簡單的機器學習模型(如XGboost),篩選相對較重要的語意標籤,得到「自殺或自傷行為」、「憂鬱與自殺意念」與「其他負向文字」三者為判斷高度危機文章的重要因素。接著將語意標註結果部分合併,把「無助感或無望感」與「生理或醫療狀況」併入「其他負向文字」,再將「正向積極文字」併入「中性或其他文字」,使語意分類模型的機器學習模型訓練與預測成為四分類模型。
訓練結果上我們可以觀察到,因分類標籤變少,四分類模型平均皆有較好表現,對於每個文句種類的分類表現也都十分均勻,F1 score約為0.7~0.76。
六、文章分類模型
針對文章分類預測模型,本計畫目標能正確偵測出有「高度危機」的網路文章,故在訓練文章分類模型時,將中度危機、低度危機、無危機三類文章合併成「中低危機」程度文章,使模型成為二分類模型。
經訓練後,此二分類文章分類模型能夠在高危機文章達到相當高準確度precision(1.00),代表預測出分類為高度危機的文章幾乎與專業人員的判斷結果符合。但由於其召回率recall僅有0.55,意即可能仍有部分屬於高度危機的文章無法被偵測出來。此處本研究亦使用ChatGPT4.0做為對照,依據同一批測試資料,可以發現ChatGPT的召回率相當高(將近1.000),但準確率較低,僅有0.714。
綜上所述,通用大型語言模型的內在設定,使其對於任何有負面情緒或自殺意念的文字都相當敏感,容易跳出警示,因此較能偵察出具負面情緒但可能無自殺危機的文章,換句話說,應用於真正的大量網路文章時,容易提供過多「偽陽性」結果,讓最終檢查人員花更多時間篩選,並非適合的模型。而在面對每小時各網路平台上成千上萬的新貼文,同時危機處理必須兼顧個人隱私保護與時效性時,降低偽陽性是較實際的需求,因此本研究採取「提高準確率」的作法較適用於實務現場[5] 。未來不排除結合不同模型的優點並擴大資料標註的數量,繼續開發出更精準且減少遺漏的網路危機文字偵測模型。
七、社群網路貼文自殺風險偵測系統
圖表五、社群網路貼文自殺風險偵測系統使用示意圖,連結如下:https://hssai-smcrisis.phys.nthu.edu.tw/

八、研究團隊
王道維教授 (國立清華大學物理學系)
李昆樺教授 (國立清華大學教育心理與諮商學系)
區國良教授 (國立清華大學學習科學研究所)
資工技術
陳致寧 (國立清華大學物理系/資工系)
馬禹平 (國立清華大學資訊工程研究所)
康云芸 (國立清華大學學習科學研究所)
資料分析
林媫柔 (國立清華大學物理系)
心理專業
梁文瑜 (國立清華大學教育心理與諮商學系)
鍾珊 (國立清華大學教育心理與諮商學系)
葉政勳 (國立清華大學教育心理與諮商學系)
王玟雅 (國立清華大學教育心理與諮商學系)
網頁設計
侯懿璠
九、參考資料
[1]NTUSD的資料與說明可參考以下網址:https://rdrr.io/rforge/tmcn/man/NTUSD.html#google_vignette
。NTUSD中包含8277個負向詞彙和2810個正向詞彙。
[2]關於本計畫的專業標註方式與使用的工具,可以參考國立清華大學人文社會AI應用與發展研究中心所錄製的「文字標註系統導論線上課程」:https://nthuhssai.site.nthu.edu.tw/p/404-1535-238010.php/ 。
[3]關於本計畫更多詳細的說明可見於研究團隊未來將逐一發表的論文(李昆樺2024)。
[4]過去一年因ChatGPT的出現,在自然語言處理的研究開始轉向以大型語言模型(Large Language Model)為基礎發展的研究。本計畫也針對若干開源的大型語言模型進行微調,但發現並沒有得到較好的結果,所以在此不作說明。
[5]在本研究中,提高對於高度危機文章召回較為簡單,只需要在訓練的時候將高度危機與中度危機的資料合併為「中高度危機」,然後與「低度或無危機」的文章區分開來,就可以達到1.00的召回率。然同時會導致對於真正高危機文章的預測準確率降低,如同ChatGPT的結果。因此在實務上,這樣的方式應無法有效的節省最終進行篩查專業人員的時間,不利於實際系統部署或危機偵測。
©copyright Artificial Intelligence for Fundamental Research (AIFR) Group